Blog
Snowplow: Unlocking Behavioral Data to Power the Next Chapter of Data Infrastructure
by Alex Sharata and Tony FlorenceJun 30, 2022
Enterprises began transitioning to the cloud nearly 20 years ago, and increased cloud adoption has also highlighted the importance of cloud data lakes and warehouses, with businesses turning to data warehouses to organize data streams from myriad sources. As investors in category-defining data infrastructure companies such as: Databricks, Tableau, DataRobot, Instabase, MuleSoft, MongoDB, and others, NEA has had a firsthand view of the trends fundamentally reshaping enterprise computing.
As small and large organizations with varying levels of DataOps sophistication continue evolving to become more data-informed, their infrastructure is shifting to become more warehouse-centric. This is not only a common trend but a best practice. There is also massive growth in the number of internal and external data systems, apps, and products being built by data teams across functions–whether they are in product, data science, sales, marketing, or engineering. These peripheral systems and data consumers need data passed down to them from an upstream warehouse. We’ve witnessed this with our involvement in companies such as Databricks. Companies with mature DataOps are making the warehouse the central source of truth powering all downstream data applications, such as AI/ML, business intelligence, product analytics, marketing, and more. As the center of gravity shifts closer to the data, one company that helps supercharge warehouse-centric architectures stood out: Snowplow–a best in class, leading data creation platform. Snowplow provides the piping that sits upstream of a warehouse and enables the collection and creation of clean, enriched, structured data that is “AI/ML-ready” and capable of powering data use cases or products.
What is data creation?
To understand data creation, we must first talk about data exhaust (and its limitations). Most data teams are dealing with data exhaust–the byproducts of disparate systems, such as analytics platforms and CRMs. Data exhaust is messy, resulting in different field types and issues with granularity, quality, and completeness. This exhaust needs significant wrangling before it can become even remotely useful. That is where data creation comes in. By investing time in the planning stages and adopting the right tooling, data teams can avoid over reliance on data exhaust. Customizing data to suit each data application allows teams to develop a structured, rich, and high quality data asset that can easily be evolved over time. This is precisely what Snowplow enables with their developer-first platform; any company can now create and consume AI-ready data as if they are Amazon or Netflix.
Snowplow collects all types of event-driven data, processes and enriches that data, models it to a schema you define, and pipes that enriched data directly to your warehouse of choice.
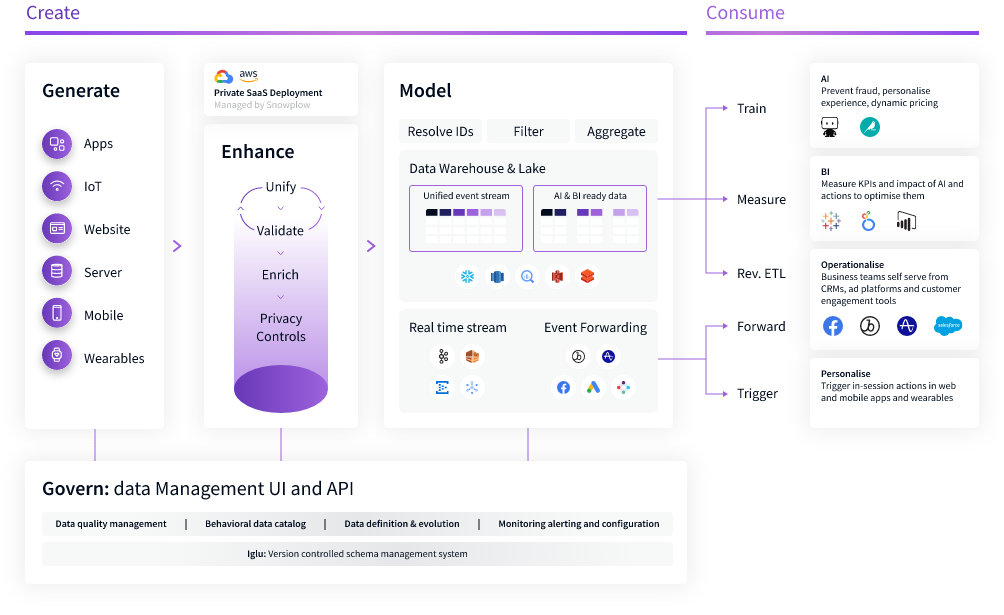 Source: https://snowplowanalytics.com/what-is-data-creation/
Source: https://snowplowanalytics.com/what-is-data-creation/We met Snowplow co-founders Alex Dean and Yali Sassoon in early 2022, and we immediately aligned with their vision of how the modern data stack is evolving and were compelled by the enterprise opportunity ahead of them. We also learned that many of our portfolio companies are paying customers and have been running Snowplow under the hood for multiple years. The customer love and positive feedback we heard was nothing short of outstanding, with customers finding Snowplow incredibly mission critical, citing the platform and team as a cornerstone of their DataOps.
We quickly came to realize that Snowplow's Behavioral Data Platform ("BDP") is much more than a front-end data scraper that simply collects data–Snowplow helps hundreds of customers drive maturation of their DataOps and hygiene by up-leveling their overall data stacks. All of our customer references pointed toward Snowplow offering the optimal level of flexibility and control over their data that is required (and is expected as table stakes) by large enterprise customers with sophisticated data architectures as well as smaller customers at the start of their journeys.
Snowplow helps companies implement two novel (yet intuitive) architectural advantages, which they helped pioneer and bring to market: 1) Customer Golden Record and 2) Composable Customer Data Platform (“CDP”). These concepts may sound new, but if you've spent any time wrestling with a 'black-box' CDP that offers little control or transparency over your data, these concepts will hit close to home.
Customer Golden Record. This is the idea of mapping all behavioral data to a common schema (or “Universal Data Language”). Having a common schema that standardizes definitions of entities and events is critical at scale–only Snowplow enables this today in an extensible manner, whereas CDPs exacerbate the problem of bad data definition hygiene.
If you have not standardized around a Customer Golden Record, then messy data hygiene eventually causes a “split brain situation.” Most marketing-focused CDPs operate as a black-box, forcing data teams to settle for their predefined schemas that are oftentimes brittle, inflexible, and obscure. Those predefined schemas might differ from team to team, and they also vary from the schemas found in your warehouse. Relying on a CDP as your source of truth results in data teams speaking "different languages" because they're not standardized around the same definitions found in a common schema. The long term benefits of setting up your infrastructure with Snowplow are manyfold. As data volumes grow and data becomes more real-time, data definition hygiene is of the utmost importance–especially for technical and non-technical users that need to consume data from the same origination point.Composable CDP. A new type of CDP where Snowplow sits upstream to your warehouse of choice and creates a pipeline to the warehouse that directly delivers accurate, enriched, customer behavioral data created from across all digital touchpoints. Snowplow lets you rest easy knowing all the data hitting your warehouse is high quality and already perfectly mapped to your common schema, or Customer Golden Record. This allows you to set up an optimal architecture using best-of-breed tooling downstream of your warehouse in order to better serve your internal data consumers. From that point forward, the high quality, AI-ready data can be piped to downstream teams and applications via reverse ETL providers like Hightouch and Census. Before you know it, you have built a Composable CDP. No black boxes dictating what your data model or schema should be. No messy, unclean data hitting your warehouse. And Snowplow now allows you to maximize the value of your full data toolchain.
You can trust the data the minute it lands in your warehouse. This provides a lot of kickbacks, mainly that you can ensure data is consistent, compliant, and informative from the moment it is created, and it can be aggregated however needed. If you make changes to your data, you can easily extend your schema accordingly. Snowplow leaves you with all your data in one table, in a clean view–a constantly evolving data cleanroom of sorts–which is the best representation of your data.
More importantly, Composable CDPs are fully modular, allowing you to build a toolchain with best of breed solutions that your team knows and loves. This minimizes vendor lock-in and maximizes flexibility thanks to Snowplow’s vendor agnosticity.
Composable CDP architectures will become an increasingly popular setup for any data organization that is maturing, because they provide an optimal way for scaled organizations with sophisticated data architectures to collect, enrich, and access behavioral customer data (and eventually all data–see below).
As an example, imagine if your sales, marketing, product, and data science teams were all using the same dataset but were not speaking the same language–that would cause a lot of friction as they try to build internally and externally-facing analytics and data products. In an ideal world, all teams would standardize around the same schema definitions so they can work cross-functionally.
Snowplow works closely with customers to help them define their Customer Golden Record. By doing a little extra legwork upfront to create an underlying common schema, data architects and downstream business users across all functions save themselves tons of headache in the future. The positive externality of adopting Snowplow is that data teams are no longer siloed and can talk to one another “in the same language,” and the data products they build can become interoperable and scale without needing to get into the weeds of redefining schemas or your data model.
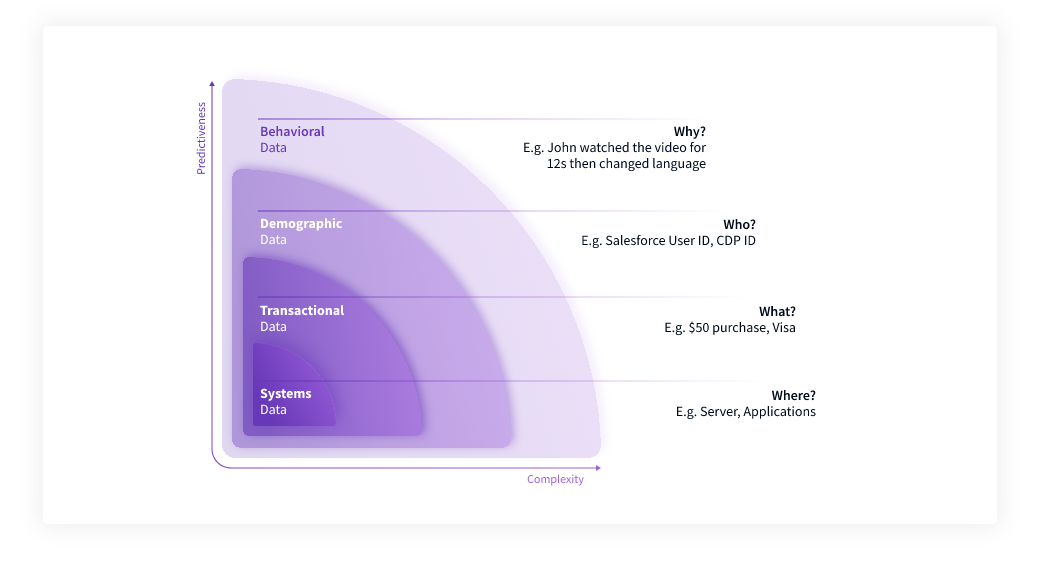 Source: <a href="Source: https://snowplowanalytics.com/what-is-data-creation/">https://snowplowanalytics.com/...
Source: <a href="Source: https://snowplowanalytics.com/what-is-data-creation/">https://snowplowanalytics.com/...Snowplow is partnering with modern ecosystem players in order to make Composable CDPs a reality. Read more on Databricks’ blog.
At the end of the day, Snowplow ultimately allows customers to create the most enriched, clean data possible–whether that’s customer data, anonymous data, or even machine data–you are left with the most informative data at the time of creation. This data is what powers a vast array of downstream analytics use cases. Snowplow removes all the ‘fluff’ and ‘noise’ that adds complexity, resulting in a crystal clear view of your most useful, predictive data. This can then inform your CDP, how you work with your customers, your decision making, and so much more. Here are a few of the most common, high-value analytics use cases clean Snowplow data helps enable:
Product analytics: develop a strong understanding of user behavior to inform product strategy and optimize the product experience.
Personalization: understand what drives user engagement, and personalize the experience in real time to drive acquisition and retention.
Attribution: assign credit to each marketing touchpoint that influences high value user behavior, bespoke to your product and user journeys.
Churn reduction: identify trends in user interaction to isolate behaviors predictive of retention and churn for better forecasting and interventions.
In addition to all these analytics use cases, customers can use clean data created by Snowplow to build data products and apps. The thesis here is simple: if you put clean, behavioral data at the heart of your products, you can deliver compelling and unique value propositions to your customers. This is enabled by a common schema that is easily extensible, paired with your data warehouse acting as your single source of truth. You can now move more applications closer to your warehouse, resulting in data apps that deliver data-driven insights much faster to end users.
The team behind Snowplow is remarkable. They’ve been in the data infrastructure space for more than a decade and are serving a critical role in the evolution of the modern data stack. That is why we are thrilled to have led Snowplow's $40M Series B financing.
Snowplow’s strong open source DNA paired with their understanding of how to build enterprise-grade products meshes well with NEA's deep heritage of investing in leading open source, data infrastructure companies. Data infrastructure has been a core thesis area for NEA for more than two decades now, and we’ve been fortunate to partner with category creators like Databricks in lakehouses and large-scale analytics, Tableau in data visualization, DataRobot in data intelligence, Elastic and Mongo in data gravity, and now we’re excited to welcome Snowplow–a pioneer in data creation.
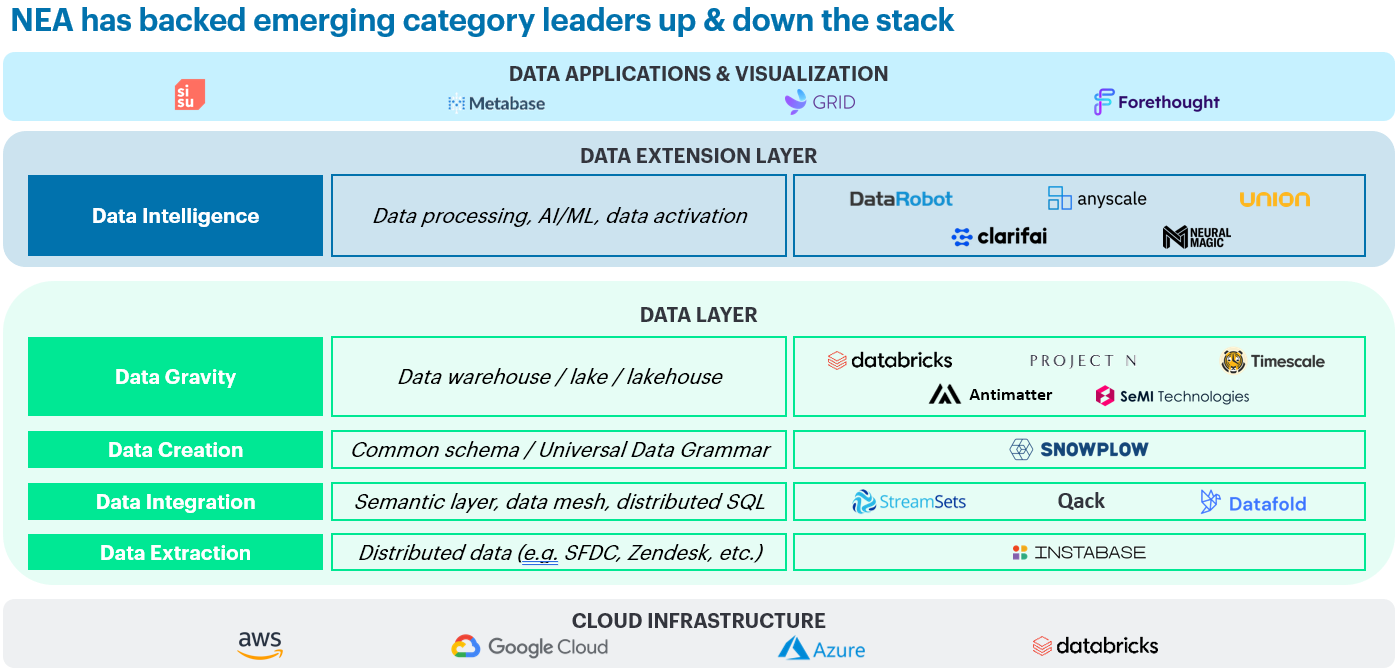 *All companies shown are active NEA investments with the exception of AWS, Google Cloud, and Azure.
*All companies shown are active NEA investments with the exception of AWS, Google Cloud, and Azure.We are grateful for the opportunity to work with Snowplow’s co-founders, Alex and Yali, and the entire Snowplow team on this next phase of growth.
*Snowplow is hiring in the US and across Europe. Want to join the Snowplow team? Check out open roles: HERE and follow them on LinkedIn / Twitter.
NEA makes no assurance that investment results obtained historically can be obtained in the future, or that any investments managed by NEA will be profitable. To the extent the content in this post discusses hypotheticals, projections, or forecasts to illustrate a view, such views may not have been verified or adopted by NEA, nor has NEA tested the validity of the assumptions that underlie such opinions. Readers of the information contained herein should consult their own legal, tax, and financial advisers because the contents are not intended by NEA to be used as part of the investment decision making process related to any investment managed by NEA.


